Building Data Lakes in AWS with S3, Lambda, Glue, and Athena from Weather Data
 By
By

Introduction
In this aricle I cover how to create a rudimentary Data Lake ontop of AWS S3 filled with historical Weather Data consumed from the World Weather Online REST API. The S3 Data Lake is populated using traditional serverless technologies like AWS Lambda, DynamoDB, and EventBridge rules along with several modern AWS Glue features such as Crawlers, ETL PySpark Jobs, and Triggers. I cap things off with a tour of AWS Athena and use it to query the resulting S3 Data Lake demonstrating the value of implementing the often merky architectural concepts behind Data Lake design.
High Level Understanding of Data Lakes
Before I get into the highly technical and practical demonstrations of building an S3 Data Lake I want to set a conceptual foundation for what a Data Lake is. A Data Lake, or at least what I've come to understand it to be, is a set of architectural concepts for managing all data formats (structured, semi, unstructured) originating from any source in a cost effective manner. A key idea with Data Lakes are to pull in data from various data silos to form a consolidated source of data in any format. Another importnat aspect of the Data Lake is that source data is kept in original form which may then undergo downstream processing (clean, consolidate, enrich, ML/AI) into new, separate, forms enabling clear data provenance (ie, chain of custody). The last important concept, and possibly the most important one, to understand about what separates a Data Lake from just a heap of files in some logical container is that the data is organized and cataloged in a way that makes it searchable, discoverable, queryable and you are able to trace down the source of the data.
Collecting Weather Data with AWS Lambda and Python
I will be collecting the data to populate the S3 Data Lake from a service provided by World Weather Online which provides historical as well as forecast weather data via a REST API. If you are following along you will need to sign up to trial this service from which you will receive an API key to access the historical weather REST endpoint.
After signing up and receiving my API key I got started by generating a boilerplate Python base AWS Serverless Application Model (SAM) project using the AWS SAM CLI.
sam init --name weather-data-collector \
--runtime python3.8 \
--package-type Zip \
--app-template hello-worldThis gives me the following project structure.
weather-data-collector
├── README.md
├── __init__.py
├── events
│ └── event.json
├── hello_world
│ ├── __init__.py
│ ├── app.py
│ └── requirements.txt
├── template.yaml
└── tests
├── __init__.py
├── integration
│ ├── __init__.py
│ └── test_api_gateway.py
├── requirements.txt
└── unit
├── __init__.py
└── test_handler.py
I remove unneeded boilerplate directories.
cd weather-data-collector
rm -r events
rm -r tests
rm -r hello_worldThen add two folders src and within src another named weather_data which will hold my AWS Lambda Python code.
Next I replace this SAM / CloudFormation template Infrastructure as Code contents shown in the code section below which creates the following resources:
- S3 bucket to serve as the Weather Data Lake repository
- Python based Lambda function for fetching historical weather data, one day at a time, for the City of Lincoln, Nebraska and saving to the S3 bucket
- Eventbridge Event Schedule for running the Lambda every few minutes which is necessary so that my daily free requests do not get exceeded during my Trial
- DynamoDB table for keeping track of the last successful date for which data was fetched
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
weather-data-collector
Sample SAM Template for weather-data-collector
Parameters:
WeatherApiKey:
Type: String
Globals:
Function:
Timeout: 300
AutoPublishAlias: live
Resources:
WeatherDataLakeS3Bucket:
Type: AWS::S3::Bucket
DeletionPolicy: Retain
Properties:
BucketName: 'tci-weather-data-lake'
WeatherDataFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/weather_data/
Handler: api.lambda_handler
Runtime: python3.8
Environment:
Variables:
WEATHER_API_KEY: !Ref WeatherApiKey
BUCKET_NAME: !Ref WeatherDataLakeS3Bucket
TABLE_NAME: !Ref WeatherDataTrackingTable
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref WeatherDataTrackingTable
- S3CrudPolicy:
BucketName: !Ref WeatherDataLakeS3Bucket
Events:
WeatherDataFetchSchedule:
Type: Schedule
Properties:
Schedule: 'rate(5 minutes)'
Name: 'weather_data_fetch_schedule'
Enabled: true
WeatherDataLogGroup:
Type: AWS::Logs::LogGroup
DependsOn: WeatherDataFunction
Properties:
LogGroupName: !Sub "/aws/lambda/${WeatherDataFunction}"
RetentionInDays: 7
WeatherDataTrackingTable:
Type: AWS::Serverless::SimpleTable
Properties:
TableName: 'weather_data_tracking'
PrimaryKey:
Name: location
Type: StringInside the src/weather_data directory I add a file named api.py and place the Python code for the Lambda function as shown below. This gets a connection to the DynamoDB table created in the template.yaml file via the AWS Boto3 SDK and the TABLE_NAME environment variable, finds the last date for which data was successfully fetched then increments it by one day in preparation for a new days worth of data to fetch. As long as the newly incremented day is in the past I proceed by using the request library to fetch a new block of weather data which is saved to S3 using Apache Hive compliant file path partitioning structure, and updates the entry in DynamoDB to the newly fetched date.
import json
import logging
import os
from datetime import date, timedelta
import boto3
import requests
import smart_open
logger = logging.getLogger()
logger.setLevel(logging.INFO)
db = boto3.resource('dynamodb')
RESOURCE = 'weather_data'
URL = 'http://api.worldweatheronline.com/premium/v1/past-weather.ashx'
def lambda_handler(event, context):
tbl = db.Table(os.environ['TABLE_NAME'])
try:
response = tbl.get_item(Key={'location': 'lincoln'})
except Exception as e:
logger.error({
'resource': RESOURCE,
'operation': 'fetch previous request date',
'error': str(e)
})
raise e
ds = date.fromisoformat(response['Item']['date'])
ds += timedelta(days=1)
if ds < date.today():
params = {
'q': 'Lincoln,NE',
'key': os.environ['WEATHER_API_KEY'],
'format': 'json',
'date': ds.isoformat(),
'tp': 1
}
try:
response = requests.get(URL, params=params)
except Exception as e:
logger.error({
'resource': RESOURCE,
'operation': 'fetch weather data',
'error': str(e)
})
raise e
data = response.json()
key_opts = {
'bucket_name': os.environ['BUCKET_NAME'],
'location': 'lincoln',
'year': ds.year,
'month': "{:02d}".format(ds.month),
'day': "{:02d}".format(ds.day),
'filename': ds.strftime('%Y%m%d.json')
}
s3_url = "s3://{bucket_name}/rawweatherdata/location={location}/year={year}/month={month}/day={day}/{filename}".format(**key_opts)
tp = {'session': boto3.Session()}
try:
with smart_open.open(s3_url, 'wb', transport_params=tp) as fo:
fo.write(json.dumps(data['data']['weather'][0]).encode('utf-8'))
except Exception as e:
logger.error({
'resource': RESOURCE,
'operation': 'save weather data to s3',
'error': str(e)
})
raise e
try:
tbl.put_item(Item={'location': 'lincoln', 'date': ds.isoformat()})
except Exception as e:
logger.error({
'resource': RESOURCE,
'operation': 'save last fetch date to dynamodb',
'error': str(e)
})
raise eTechnical Explanation: Data Lake Partitions
I want to take a moment to further explain what is going on with the funny looking file path (aka object key) for the JSON file being saved to S3. The path between the bucket name and the filename is composed of carefully selected partitions. A partition is way to use directory structures to categorize or organize data within a Data Lake using a clear naming convention that is meaningful and navigable. The concept of Partitions within you S3 Data Lake is particularly important when it comes to using Glue Crawlers to catalog S3 datasets.
There are two common approaches, that I know of, which are used to create partitions for data sets within a Data Lake which I'll briefly cover here. However, the AWS Glue Crawler Partition Docs do a pretty good job of explaining this concept as well so please see what they have to say on the topic as well.
The first approach I've seen is simply accomplished by placing keywords as directory names that you are likely to filter and group your dataset by. For the example data I'm working with here there interest in collecting data for city of lincoln broken down by year, month and day. Thus, the simplest way to create a directory partition structure to convey this information is shown below.
lincoln
└── 2020
├── 01
│ ├── 01
│ ├── 02
| ...
│ └── 31
├── 02
│ ├── 01
│ └── 02
| ...
│ └── 28
└── 03
├── 01
└── 02
...
└── 31A slightly more complex yet more information rich way is to name the directories with key / value pairs as I've done in the code for the weather data fetching Lambda function and depicted below. The benefit of this is that Glue will use the name / value pairs to automaticaly give the correct names to your partitions when Glue Crawlers infer the schema.
location=lincoln
└── year=2020
├── month=01
│ ├── day=01
│ ├── day=02
| ...
│ └── day=31
├── month=02
│ ├── day=01
│ ├── day=02
| ...
│ └── day=28
└── month=03
├── day=01
├── day=02
...
└── day=31 Back in the root of my AWS SAM project I now build and deploy the Serverless application stack.
First build the project.
sam build --use-containerThen run the deploy command in guided mode making sure to pass in the API key I got from World Weather Online when the SAM CLI prompts me for the WeatherApiKey parameter.
sam deploy --guidedOnce the application stack has been successfully deployed there is one more important step I needed in order to get the data fetches going, and that is to create an entry in the DynamoDB table representing the date I want to start fetching data from for the lincoln location. I'm actually really quite excited for this part because it gives me the opportunity to use the new PartiQL Editor right in the DynamoDB AWS Management Console.
Create the table item.

Then query it!

Now if I wait at least 5 minutes I will see weather data fetches show up in my S3 bucket using either the S3 console or AWS CLI like so.
$ aws s3 ls s3://tci-weather-data-lake/ --recursive
2021-02-21 20:37:41 rawweatherdata/location=lincoln/year=2020/month=01/day=02/20200102.json
2021-02-21 20:42:40 rawweatherdata/location=lincoln/year=2020/month=01/day=03/20200103.json
2021-02-21 20:47:39 rawweatherdata/location=lincoln/year=2020/month=01/day=04/20200104.jsonExcellent! Data is being collected and fed into the S3 Data Lake so now its time to move on to getting AWS Glue setup.
Automatic Schema Detection of S3 Datasets with Glue Crawlers
Alright, I've actually let the SAM serverless app run for a little more that a day so I now have daily weather data for the City of Lincoln going back to January 1, 2020. With the raw JSON data from the worldweatheronline.com API nicely loaded into the S3 bucket I can create a Glue Crawler to collect some useful metadata about the raw weather dataset such as the available partitions along with it's schema and associated data types. All this occurs via predefined algorithms wrapped up in what AWS refer to as classifiers.
For this Glue Crawler I will configure it to crawl the rawweatherdata directory within my previously created S3 bucket. I also configure this crawler to be associated with a database I define within the Glue Metadata Catalog which will contain tables of metadata (schemas, datatypes, classification, ect...) for each logically distinct datasets as identified by the Glue Classifiers.
I will again use CloudFormation Infrastructure as Code to define the Database in the Glue Catalog along with the Glue Crawler in the same SAM / CloudFormation template I defined my Lambda, EventBridge rule, and DynamoDB table in as shown below.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
weather-data-collector
Sample SAM Template for weather-data-collector
Parameters:
WeatherApiKey:
Type: String
Globals:
Function:
Timeout: 300
AutoPublishAlias: live
Resources:
WeatherDataLakeS3Bucket:
Type: AWS::S3::Bucket
DeletionPolicy: Retain
Properties:
BucketName: 'tci-weather-data-lake'
WeatherDataFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/weather_data/
Handler: api.lambda_handler
Runtime: python3.8
Environment:
Variables:
WEATHER_API_KEY: !Ref WeatherApiKey
BUCKET_NAME: !Ref WeatherDataLakeS3Bucket
TABLE_NAME: !Ref WeatherDataTrackingTable
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref WeatherDataTrackingTable
- S3CrudPolicy:
BucketName: !Ref WeatherDataLakeS3Bucket
Events:
WeatherDataFetchSchedule:
Type: Schedule
Properties:
Schedule: 'rate(3 minutes)'
Name: 'weather_data_fetch_schedule'
Enabled: true
WeatherDataLogGroup:
Type: AWS::Logs::LogGroup
DependsOn: WeatherDataFunction
Properties:
LogGroupName: !Sub "/aws/lambda/${WeatherDataFunction}"
RetentionInDays: 7
WeatherDataTrackingTable:
Type: AWS::Serverless::SimpleTable
Properties:
TableName: 'weather_data_tracking'
PrimaryKey:
Name: location
Type: String
WeatherGlueDefaultIamRole:
Type: 'AWS::IAM::Role'
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- glue.amazonaws.com
Action:
- 'sts:AssumeRole'
Path: /
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
WeatherGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: "weatherdata"
Description: Glue metadata catalog database weather dataset
RawWeatherGlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: 'rawweather'
DatabaseName: !Ref WeatherGlueDatabase
Description: Crawls the Raw Weather Data
Role: !GetAtt WeatherGlueDefaultIamRole.Arn
Targets:
S3Targets:
- Path: !Sub "s3://${WeatherDataLakeS3Bucket}/rawweatherdata"
Schedule:
ScheduleExpression: cron(0 1 * * ? *) # run every day at 1 amThe above new CloudFormation resources create a Glue Catalog database named weatherdata along with a Glue Crawler for inferring metadata on the raw weather in S3 which is persisted in a table in the Glue database.
I again use the same set of build and deploy commands with the SAM CLI as shown below.
sam build --use-container
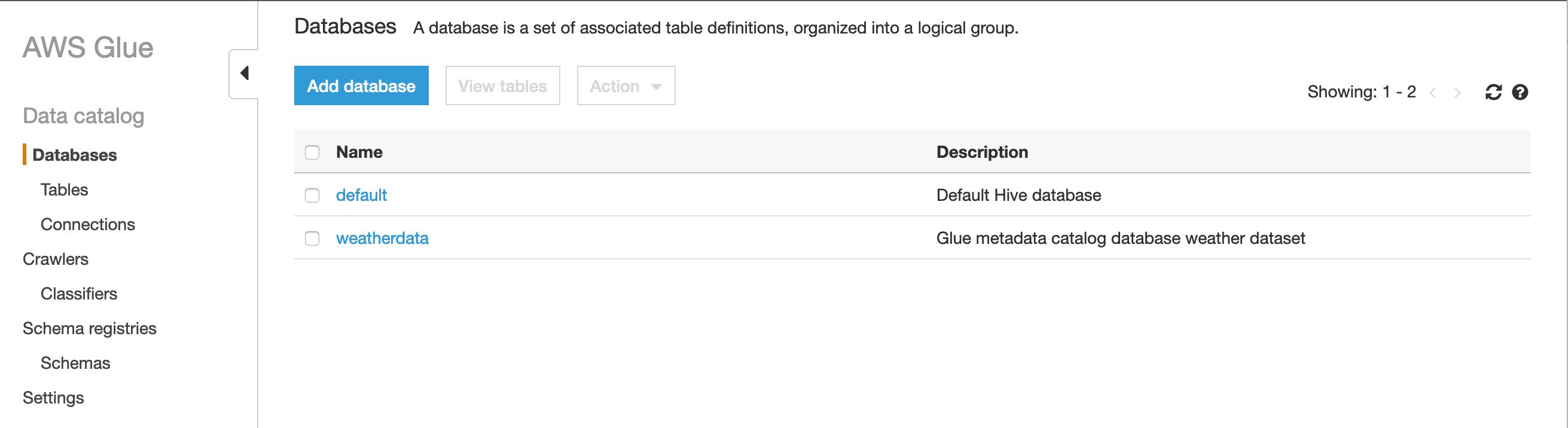
sam deployAfter the deployment is complete I head over the Glue dashboard within the AWS Console and I can see that the weatherdata database has been added in the Glue Catalog list of databases.
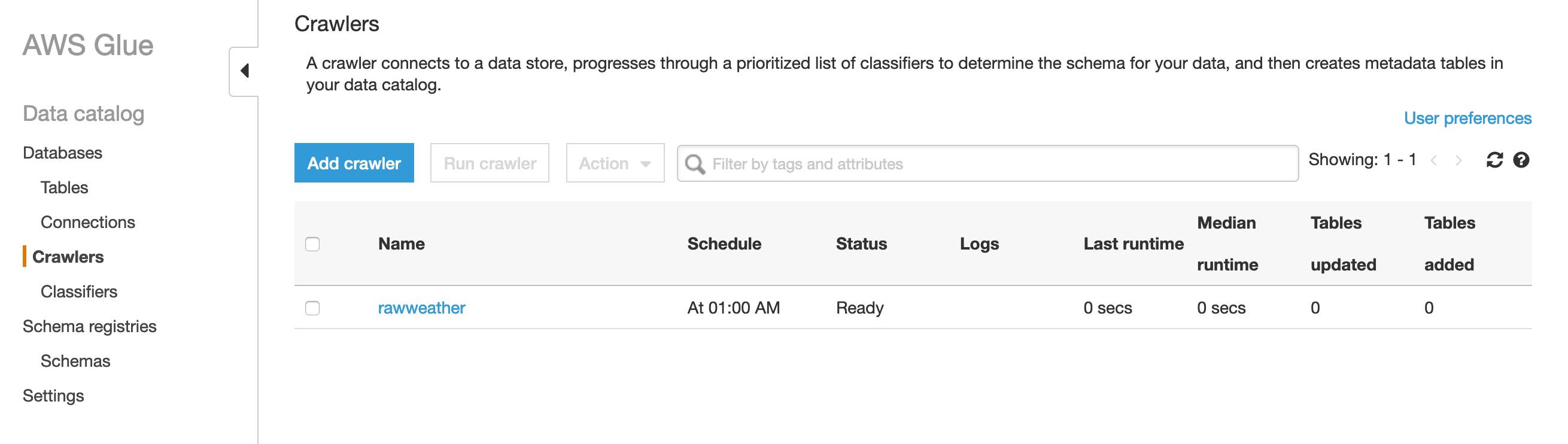
Similarly, if I head over to the Crawlers view I see the new crawler as well.
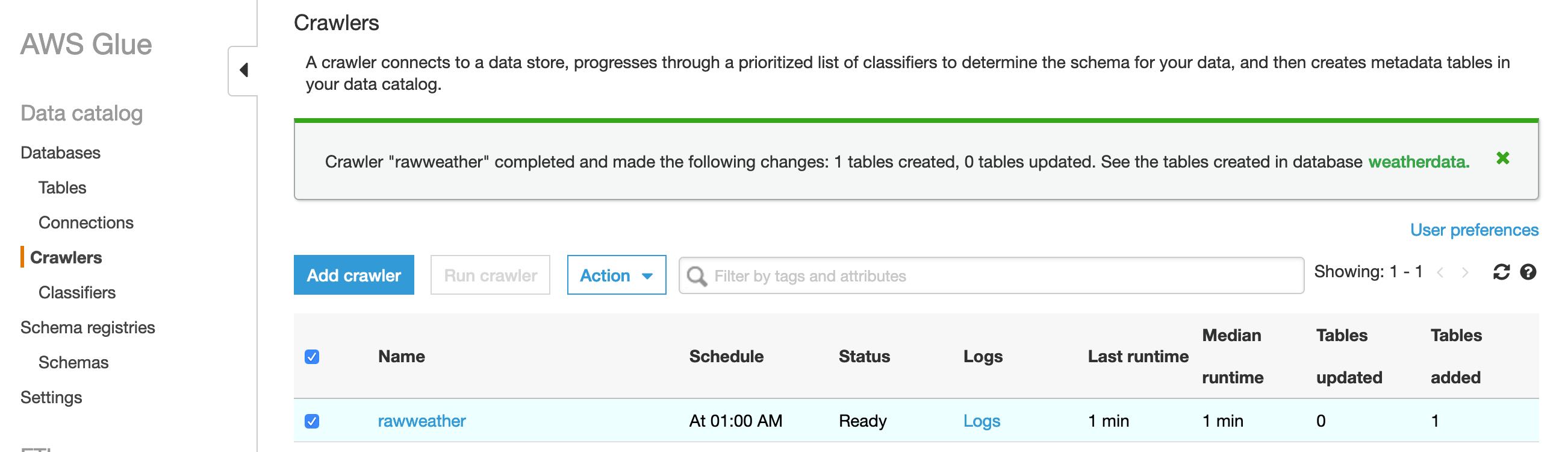
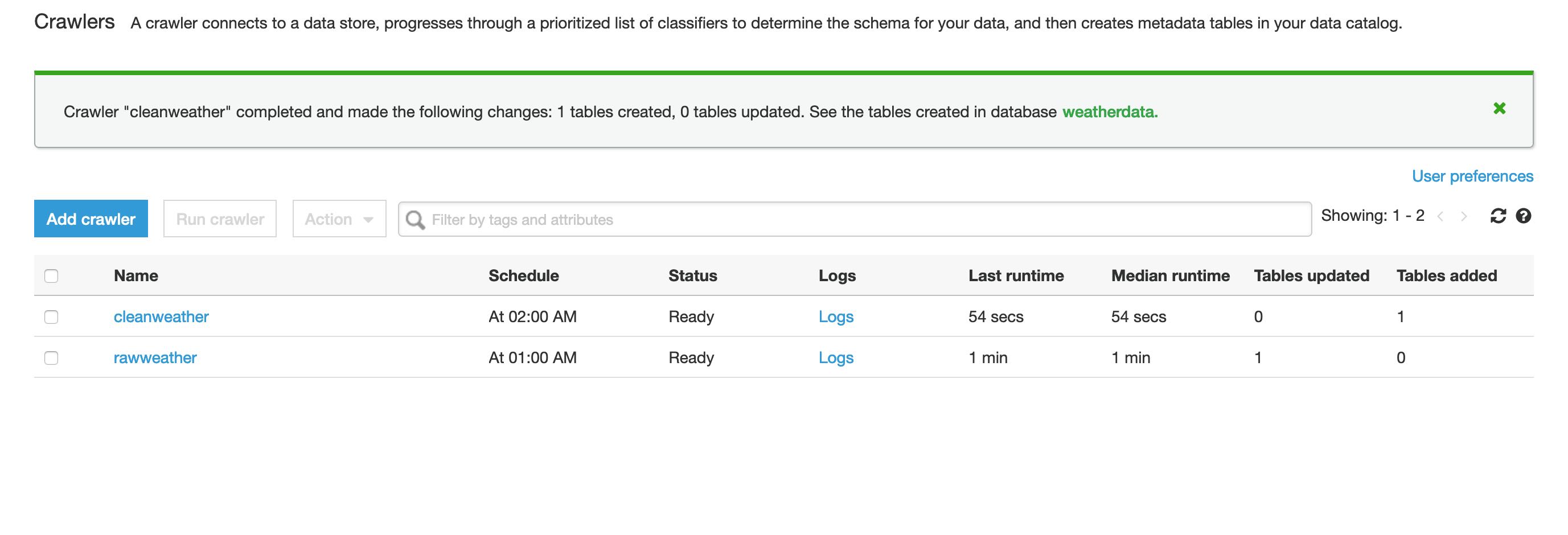
Rather than waiting for the crawler to run at 1AM tomorrow I can select it's row in the crawlers table and click the Run crawler button so it runs on demand. When it is done running I get a message banner stating that it finished and has added a new table in the Glue Catalog database.
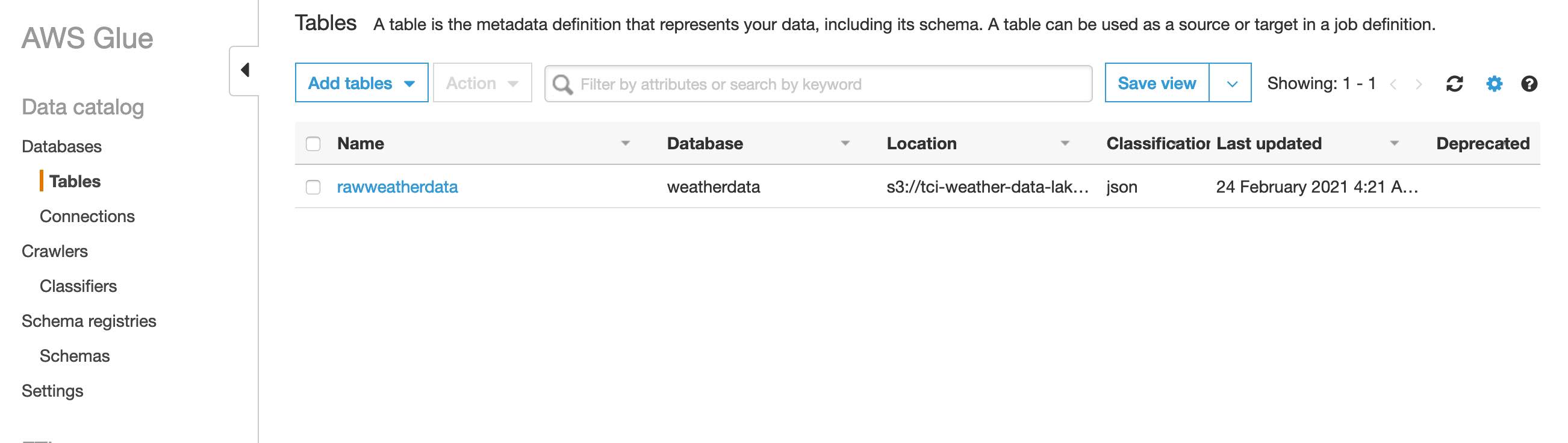
Now if I click on the tables menu beneath the Databases section I see that there is a new table named after the crawler that produced it "rawweather".
Clicking its link in the HTML table shows me the schema and other related metatdata that the crawler algorithms determined.

Notice that the schema the crawler inferred identified the partitions that I created as part of each S3 object's key (aka file path) but, the majority of the columns are of type string which isn't really what we want from a analytics standpoint. Similarly, if I click on the array datatype for the hourly column a popup is displayed showing me nested data representing various measurements for each hour of the day.

It would be much more meaningful if I could have those string types converted to appropriate numeric types as well as derive some summary statistics on the hourly measurements in the multi-valued arrays in the hourly column. This is exactly what the Spark based Glue ETL jobs were designed to accomplish and a perfect segue into the next section.
Cleaning Data with Glue ETL Spark Jobs
Glue ETL jobs are a very cool and extremely powerful offering provided within the AWS Glue service. What they provide are a way to write Spark based data processing tasks in a fully managed, scalable, distrubuted Apache Spark Computing environment that is essentially an on demand service. Glue ETL jobs can work in concert with the Glue Metadata Catalog tables to efficiently access, or query, associated data stores which in this example is S3 object storage.
In this section I configure a Glue ETL pyspark job to execute at the conclusion of each successful run of the Glue Crawler previously defined. This Glue ETL job will convert column field values to appropriate data types such as FloatType, IntegerType, and DateType as well as parse the hourly column fields to produce summary statistics like min, max and average for humidity and pressure then add them as columns to the dataset. I also drop the hourly and astronomy multi-valued columns all together along with the temperature columns expressed in Celsius. Then I finally save the resultant cleaned data to a separate directory in the same S3 bucket in the analytics friendly, columar oriented, Apache Parquet format for efficient downstream analysis in other services such as AWS Athena.
Produced below is the PySpark script to be ran in a Glue ETL Job as described above.
import logging
import sys
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.utils import getResolvedOptions
import numpy as np
import pandas as pd
from pyspark import SparkContext
from pyspark.sql import functions as F
from pyspark.sql.session import SparkSession
from pyspark.sql.types import FloatType, StringType, IntegerType, DateType
logger = logging.getLogger()
logger.setLevel(logging.INFO)
expected_args = ["s3_bucket", "glue_database", "rawweather_table"]
args = getResolvedOptions(sys.argv, expected_args)
glue_db = args['glue_database']
s3_bkt = args['s3_bucket']
rawweather_tbl = args['rawweather_table']
output_s3_path = "s3://{s3_bkt}/cleanweather".format(s3_bkt=s3_bkt)
logger.info({
'glue_database': glue_db,
's3_bucket': s3_bkt,
'rawweather_table': rawweather_tbl,
'output_s3_path': output_s3_path
})
spark = SparkSession(SparkContext.getOrCreate())
glue_ctx = GlueContext(SparkContext.getOrCreate())
raw_dyf = glue_ctx.create_dynamic_frame.from_catalog(database=glue_db, table_name=rawweather_tbl)
def process_hourly(hours, key, fn):
nums = []
for hr in hours:
if hr[key]:
try:
num = float(hr[key])
if pd.notnull(num):
nums.append(num)
except Exception as e:
logger.error({
"error": str(e),
"message": "error converting {} to float".format(hr[key])
})
raise e
if nums:
return float(fn(nums))
return np.nan
avg_humidity = F.udf(lambda hours: process_hourly(hours, 'humidity', np.mean), FloatType())
avg_pressure = F.udf(lambda hours: process_hourly(hours, 'pressure', np.mean), FloatType())
min_humidity = F.udf(lambda hours: process_hourly(hours, 'humidity', min), FloatType())
min_pressure = F.udf(lambda hours: process_hourly(hours, 'pressure', min), FloatType())
max_humidity = F.udf(lambda hours: process_hourly(hours, 'humidity', max), FloatType())
max_pressure = F.udf(lambda hours: process_hourly(hours, 'humidity', max), FloatType())
total_precipMM = F.udf(lambda hours: process_hourly(hours, 'precipMM', sum), FloatType())
clean_df = raw_dyf.toDF().withColumn(
'avgHumidity', avg_humidity('hourly')
).withColumn(
'avgPressure', avg_pressure('hourly')
).withColumn(
'minHumidity', min_humidity('hourly')
).withColumn(
'minPressure', min_pressure('hourly')
).withColumn(
'maxHumidity', max_humidity('hourly')
).withColumn(
'maxPressure', max_pressure('hourly')
).withColumn(
'totalPrecipMM', total_precipMM('hourly')
).withColumn(
'maxtempF', F.col('maxtempF').cast(FloatType())
).withColumn(
'mintempF', F.col('mintempF').cast(FloatType())
).withColumn(
'avgtempF', F.col('avgtempF').cast(FloatType())
).withColumn(
'totalSnow_cm', F.col('totalSnow_cm').cast(FloatType())
).withColumn(
'sunHour', F.col('sunHour').cast(FloatType())
).withColumn(
'uvIndex', F.col('uvIndex').cast(IntegerType())
).withColumn(
'date', F.col('date').cast(DateType())
).drop('hourly', 'astronomy', 'mintempC', 'maxtempC', 'avgtempC')
clean_dyf = DynamicFrame.fromDF(
clean_df.repartition("location", "year", "month"),
glue_ctx,
'cleanweather'
)
glue_ctx.write_dynamic_frame.from_options(
frame=clean_dyf,
connection_type="s3",
connection_options={"path": output_s3_path},
format="parquet"
)Next I need to give the script a place to live in S3 where the Glue ETL Job can reference it from. This is easily done from the command line with the AWS CLI like so.
First create an S3 bucket.
aws s3 mb s3://my-demo-glue-scripts --region us-east-2I follow this by copying up the script to the new bucket.
aws s3 cp etl_raw_weather_data_cleaner.py s3://my-demo-glue-scripts/ That leaves my ending full script path as s3://my-demo-glue-scripts/etl_raw_weather_data_cleaner.py
Up next on the agenda is to define some new Glue resources in the SAM / CloudFormation template consisting of a Glue ETL Job along with a Glue ETL Trigger to initiate the job upon successful runs of the raw weather data Crawler. There is also an additional new Glue Crawler to catalog the new cleaned weather data the PySpark ETL job generates.
It is worth noting how configuration parameters are being passed between the CloudFormation Glue Job resouces using the DefaultParameter field in the CloudFormation resource and then subsequently parsed and used to dictate the flow and sourcing of data within the above PySpark Glue script. Also note that I added a new SAM / CloudFormation Parameter for providing the path to the Glue PySpark script on S3 which is then referenced from the Glue ETL Job resource with the intrinsic Ref function.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
weather-data-collector
Sample SAM Template for weather-data-collector
Parameters:
WeatherApiKey:
Type: String
GlueEtlScriptS3Path:
Type: String
Globals:
Function:
Timeout: 300
AutoPublishAlias: live
Resources:
WeatherDataLakeS3Bucket:
Type: AWS::S3::Bucket
DeletionPolicy: Retain
Properties:
BucketName: 'tci-weather-data-lake'
WeatherDataFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/weather_data/
Handler: api.lambda_handler
Runtime: python3.8
Environment:
Variables:
WEATHER_API_KEY: !Ref WeatherApiKey
BUCKET_NAME: !Ref WeatherDataLakeS3Bucket
TABLE_NAME: !Ref WeatherDataTrackingTable
Policies:
- DynamoDBCrudPolicy:
TableName: !Ref WeatherDataTrackingTable
- S3CrudPolicy:
BucketName: !Ref WeatherDataLakeS3Bucket
Events:
WeatherDataFetchSchedule:
Type: Schedule
Properties:
Schedule: 'rate(3 minutes)'
Name: 'weather_data_fetch_schedule'
Enabled: true
WeatherDataLogGroup:
Type: AWS::Logs::LogGroup
DependsOn: WeatherDataFunction
Properties:
LogGroupName: !Sub "/aws/lambda/${WeatherDataFunction}"
RetentionInDays: 7
WeatherDataTrackingTable:
Type: AWS::Serverless::SimpleTable
Properties:
TableName: 'weather_data_tracking'
PrimaryKey:
Name: location
Type: String
WeatherGlueDefaultIamRole:
Type: 'AWS::IAM::Role'
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- glue.amazonaws.com
Action:
- 'sts:AssumeRole'
Path: /
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
WeatherGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: "weatherdata"
Description: Glue metadata catalog database weather dataset
RawWeatherGlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: 'rawweather'
DatabaseName: !Ref WeatherGlueDatabase
Description: Crawls the Raw Weather Data
Role: !GetAtt WeatherGlueDefaultIamRole.Arn
Targets:
S3Targets:
- Path: !Sub "s3://${WeatherDataLakeS3Bucket}/rawweatherdata"
Schedule:
ScheduleExpression: cron(0 1 * * ? *) # run every day at 1 am
CleanWeatherGlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: 'cleanweather'
DatabaseName: !Ref WeatherGlueDatabase
Description: Crawls the Clean Weather Data
Role: !GetAtt WeatherGlueDefaultIamRole.Arn
Targets:
S3Targets:
- Path: !Sub "s3://${WeatherDataLakeS3Bucket}/cleanweather"
Schedule:
ScheduleExpression: cron(0 2 * * ? *) # run every day at 2 am
RawWeatherCleanerGlueEtlJob:
Type: AWS::Glue::Job
DependsOn: RawWeatherGlueCrawler
Properties:
Description: PySpark Glue job cleans, reformats, and enriches raw Weather Data
GlueVersion: 2.0
Command:
Name: glueetl
ScriptLocation: !Ref GlueEtlScriptS3Path
PythonVersion: 3
MaxCapacity: 10
MaxRetries: 2
Role: !GetAtt WeatherGlueDefaultIamRole.Arn
Timeout: 5
DefaultArguments: {
"--s3_bucket": !Sub "${WeatherDataLakeS3Bucket}",
"--glue_database": !Sub "${WeatherGlueDatabase}",
"--rawweather_table": "rawweatherdata",
"--cleanweather_table": "cleanweather"
}
RawWeatherCleanerGlueTrigger:
Type: AWS::Glue::Trigger
DependsOn: RawWeatherCleanerGlueEtlJob
Properties:
Actions:
- JobName: !Ref RawWeatherCleanerGlueEtlJob
Description: Initiates Glue PySpark Job that processes the raw weather data
Predicate:
Conditions:
- CrawlerName: !Ref RawWeatherGlueCrawler
CrawlState: SUCCEEDED
State: SUCCEEDED
LogicalOperator: EQUALS
Type: CONDITIONAL
StartOnCreation: trueAgain, the SAM project will need built and deployed but, this time the deploy command should be ran in interactive mode using the --guided flag so that it prompts for the path to the PySpark script uploaded to S3 earlier.
sam build --use-container
sam deploy --guidedAfter this finishs deploying I can again go back to the Glue service console and click on Jobs menu item on the left to view my new Glue ETL Job.

Unfortunately Glue Jobs that are initiated by triggers that are dependent on other Jobs or Crawlers will not run when the upstream Job or Crawler is ran on demand so, testing the workflow of the Crawler succeeding then initiating the new ETL job requires waiting until the Crawlers scheduled run of at 1AM. I can however, manually initiate the new Glue Job from the console independently as shown below.

After about a minute the history tab at the bottom of the jobs UI shows the ETL job succeeded.
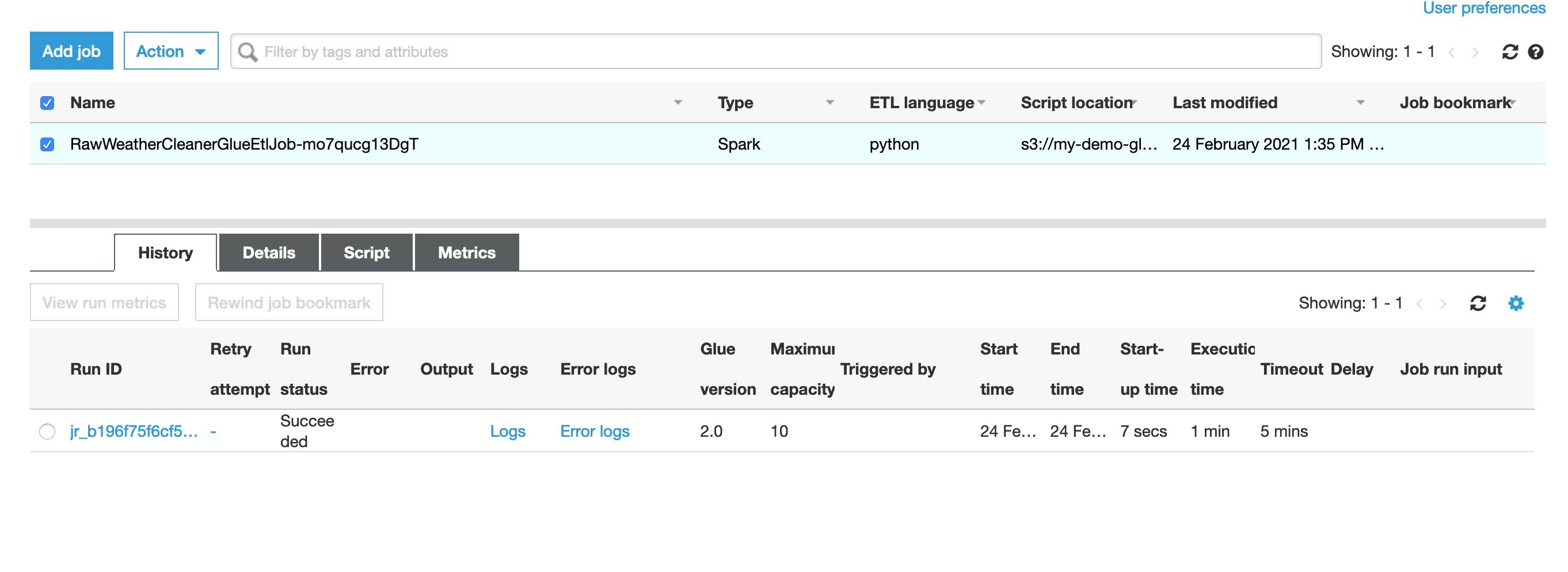
The last thing to do now is go manually kick off the new Clean Weather data Glue Crawler so that the cleaned weather data just created in the ETL job gets populated in the Glue Metadata Catalog as a new table.
Lastly, I head over to the Glue Database Tables view and select the new cleanweather table to view the schema and associated metadata as shown below.

This completes my demo of using Glue to catalog and process the S3 data lake populated from the worldweatheronline.com API. In the next section I briefly cover using AWS Athena to query these two datasets.
Query with Athena
In this section I demonstrate using AWS Athena which is a fully managed, serverless and, interactive query service for data stored on S3. It can effectively query data in various formats including structure, semi-structured, and unstructured directly in S3 without needing to copy it into the program unlike other Hadoop based query technologies that must copy data into the Hadoop File System.
Alright, enough with the fluff talk... lets get on with querying this data!
I search for Athena in the search bar at the top of the AWS Management Console and click to load the page. If you have never used Athena before the UI should be prompting you to select an S3 bucket that Athena can use for storing query results. Please do so now before going further if you are following along.
When the Athena Query Editor page is displayed there will be a control pane on the left from which I choose the weatherdata database that was created in the section on AWS Glue previously.
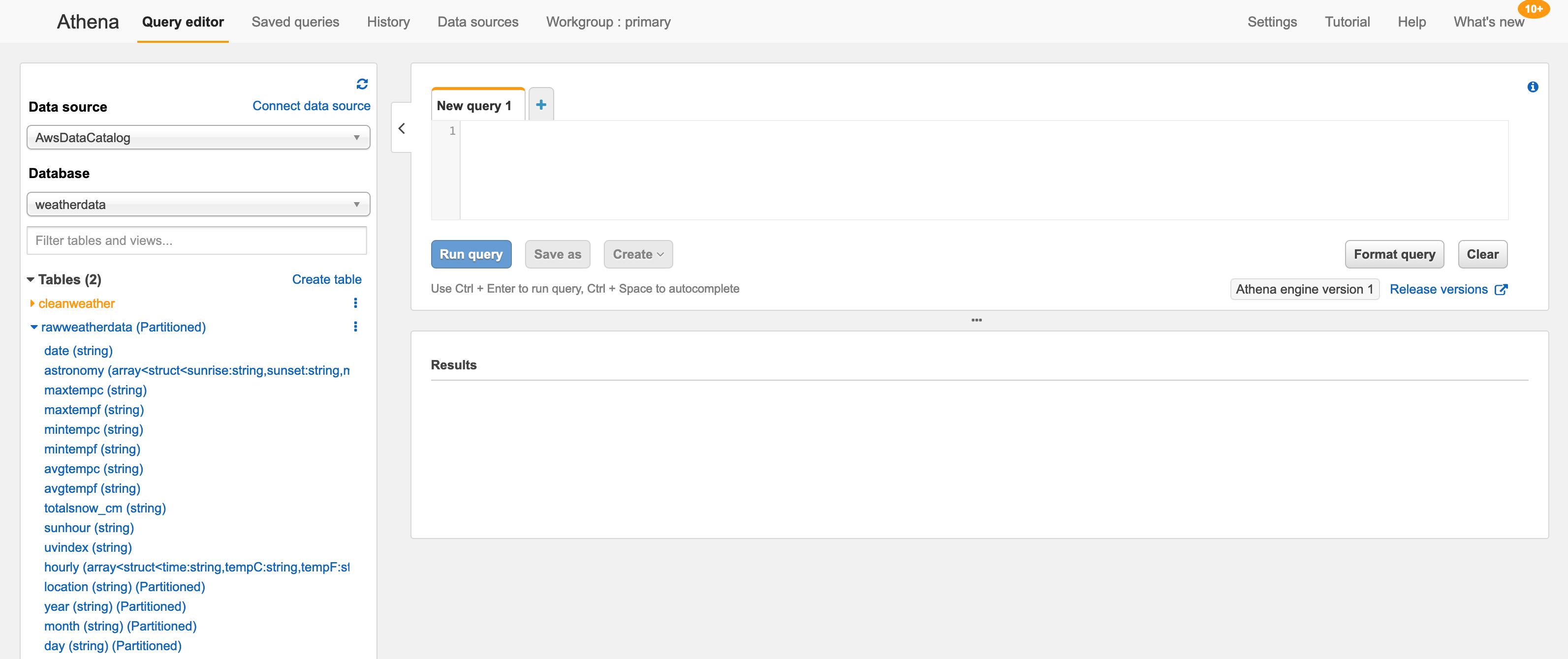
Upon selection of the weatherdata database my two tables defined by the Glue Crawlers are populated in the tables section. In the above image you can see that by expanding the rawweatherdata table the exact same schema we saw previosly in the Glue section is displayed.
I will now query the data in this rawweatherdata table as shown below.
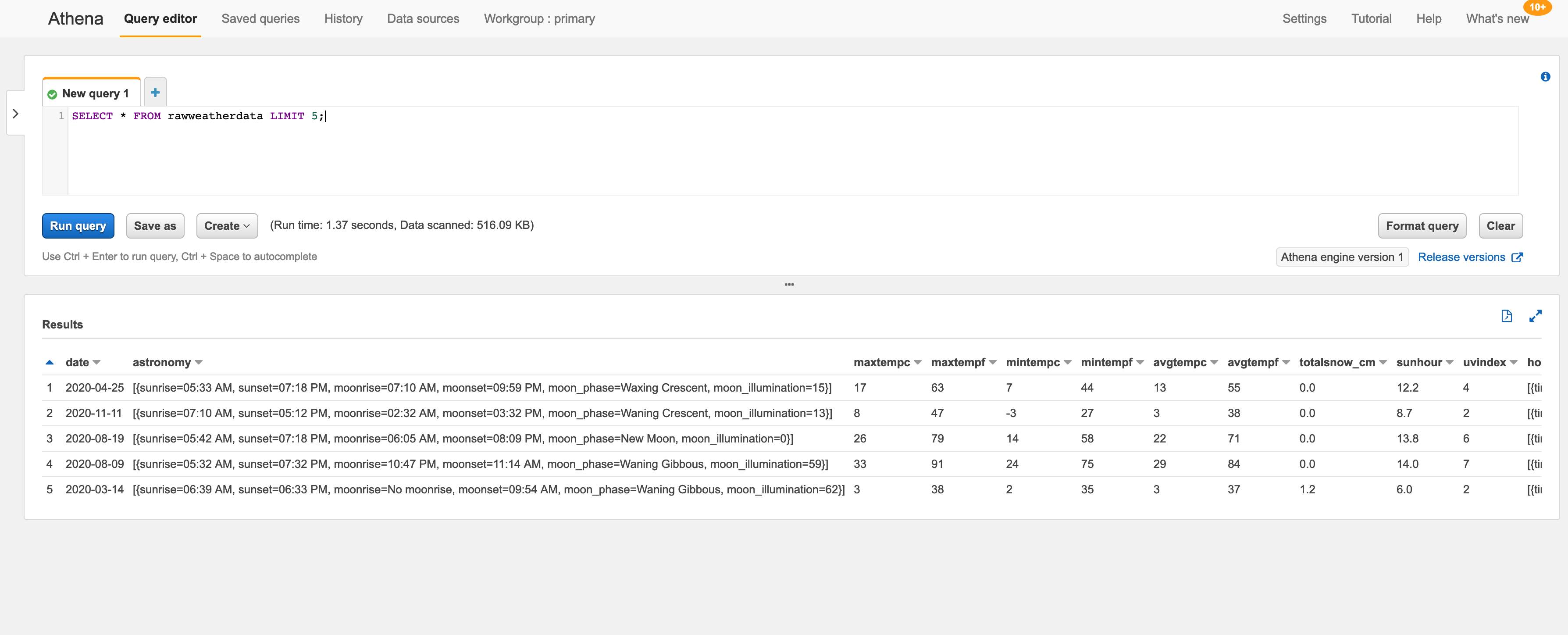
Magnificently the S3 data is returned in all its messy nested glorious details which highlights the needed effort I took to clean the raw data into a more consumable form.
I'll end by querying the cleanweather table doing something a little more interesting. This time I'll use the same ole familiar ANSI 2003 SQL we've all come to know and love to get monthly average, min and max temperatures over the year 2020 for the City of Lincoln.

Pretty neat stuff right?
Resources to Learn More About High Performance Spark Computing
- A fantastic book on Modern Spark computing and one that has been instrumental in developing my understanding of programming in Spark is Learning Spark: Lightening-Fast Data Analytics
- If you are looking for an introductory article on PySpark or for some more examples to add to your PySpark toolset please have a look at my article Example Driven High Level Overview of Spark with Python
thecodinginterface.com earns commision from sales of linked products such as the book suggestions above. This enables providing high quality, frequent, and most importantly FREE tutorials and content for readers interested in Software Engineering so, thank you for supporting the authors of these resources as well as thecodinginterface.com
Conclusion
In this article I have walked through the process of building and working with a rudimentary Data Lake on S3 populated with real world historical weather data from a consumable REST API using several powerful AWS services and popular open source Big Data technologies.